
128
Просмотры

Последнее обновление

Преобразование «больших данных» в значимые результаты может показаться сложным. Но как только вы поймете, что это такое и как оно работает, сделать его осмысленным не так сложно.
На протяжении многих лет многие модные слова стали модными во многих отраслях. Мало кто стал таким популярным и так долго, как большие данные. Но что такое большие данные?
Большие данные относятся к виртуальному океану информации из различных источников, которые анализируются и фильтруются таким образом, чтобы получить значимые и действенные результаты.
Процесс преобразования «больших данных» в значимые результаты может показаться сложным и трудным. Однако, как только вы поймете, что такое большие данные и как они работают, понимание того, как сделать их значимыми, не кажется таким сложным.
Когда вы слышите, как люди говорят о «больших данных», они обычно размахивают руками и громкими словами. Но когда вы сводите всю гиперболу, фактические «данные» на самом деле представляют собой множество множественных потоков ввода данных.
Чтобы понять это, пример может помочь. Допустим, вы управляете компанией по производству зонтов. Ваш отдел маркетинга ищет способ лучше предсказать, когда спрос на рынке будет расти.
До появления больших данных маркетологи изучали тенденции рынка, рассылали опросы клиентов и многое другое.

Они будут собирать все эти данные и хранить их во внутренних базах данных своей компании. Кто-то может даже отвечать за обновление данных маркетинговых исследований на ежегодной или квартальной основе.
Однако появление больших данных расширяет возможности проведения такого рода исследований. В частности, большие данные особенно эффективны при выявлении важных тенденций или событий практически в реальном времени.
Входные данные для этого вида анализа «больших данных» могут включать потоки данных в реальном времени путем написания кода, который подключается к Интерфейс прикладного программирования (API) из многих различных компаний, которые сделали эти данные общедоступными:
Чтобы использовать большие данные, маркетинговая команда этой компании должна, в некоторых случаях, установить новые технологии.
Это может включать технологию Интернета вещей (IoT) в розничных магазинах, которая отслеживает и сообщает о поведении потребителей. Или может потребоваться, чтобы программист написал код, необходимый для взаимодействия с API Twitter, чтобы отфильтровывать любые твиты с упоминанием «зонтиков» или названия компании.
Каждая из этих технологий теперь доступна благодаря Интернету. Интернет позволяет любому подключаться к потокам данных со всего мира.
Вот как установка в нашем собственном примере может работать в этом случае.
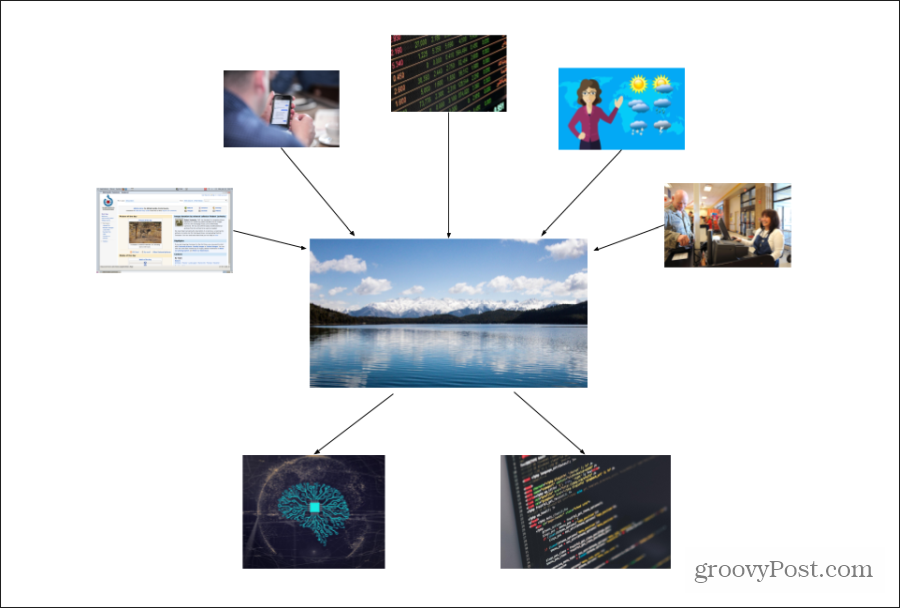
На этой диаграмме показано, как данные попадают в «озеро данных» компании из разных источников. Входящие данные могут быть структурированы по-разному, но важно собрать как можно больше данных из всех источников.
В отличие от базы данных, которая содержит структурированные данные, организованные в определенные столбцы и строки, озеро данных является огромным хранилищем для многих различных форм данных.
Данные, которые хранятся, могут быть структурированными или неструктурированными. Это означает, что он может иметь структурированные строки и столбцы, а может и нет. Данные могут быть строками, использующими специальное форматирование для разделения данных. Каждый источник данных может отправлять данные в озеро данных в любой удобной для них форме.
Изобразите озеро данных, как огромную библиотеку, которая содержит множество форм мультимедиа, таких как книги, изображения на микрофишах и видео на DVD.

Вообразите инженера в области цифровой разведки и анализа данных как покровителей этой библиотеки. Эти покровители могут извлекать данные из книг, микрофиш и DVD-дисков в цифровом виде, находить способы смешивать и комбинировать эти данные и узнавать, как эти данные коррелируют.
Из этих уроков получается действительный, действенный интеллект. Некоторые из них из нашего примера могут включать:
Все эти знания могут побудить маркетинговую команду инвестировать в большее количество рекламы в географическом плане, где спрос на зонтичные продажи значительно выше. Производственные операции могут также перенести их производственные усилия в те районы мира, где продажи, скорее всего, будут расти.
Таким образом, используя большие данные, любая компания может оптимизировать свой маркетинг и операции.
Следующий вопрос: как компании обрабатывают такие большие объемы данных и выявляют тенденции?
Этот вид обработки данных требует огромных компьютерных ресурсов. Настолько, что компании больше не используют большие мэйнфрейм-компьютеры локально, как раньше. Многие из этих сервисов в настоящее время являются покупками из облака. Службы облачных данных, такие как Apache Hadoop, предлагают множество компьютерных узлов в большой облачной сети. Каждый из этих узлов вносит свой вклад в вычислительную мощность, необходимую для анализа огромных потоков данных из нескольких источников.

Этот вид вычислительной мощности является сердцем машинного или цифрового интеллекта и анализа данных. Hadoop - это программная структура, которая обеспечивает всю эту мощную вычислительную мощность, необходимую для инженеров цифровой разведки.
Как только вычислительный движок производит действенные интеллектуальные данные, они обычно доставляются в компанию в виде информационных панелей или отчетов.
Правда в том, что «большие данные» - это больше, чем просто корпоративный язык. Многие компании понимают, что, используя более эффективные данные, они могут достичь многочисленных достижений.
В то время как большая часть того, что было достигнуто за последние годы большими данными, остается практически незаметной для общественности, большие данные фактически оказали значительное влияние на повседневную жизнь людей во всем мире.